Description of the video:
[Victor Borden] Thank you for joining us today. And we thank our AIR and AV Media colleagues for their providing this venue and for their ongoing support. We will present to you today a way of thinking about and approaching institutional research work that responds to several significant trends that are reshaping educational programs and practices. The model we present, which we have labeled the Insight Engine, provides a framework for expanding the reach and potency of institutional research. And perhaps most importantly, for integrating that work with our colleagues' efforts to deliver high-quality post-secondary education and training for an increasingly diverse population of learners. To paraphrase one of my idols. There is a fifth dimension beyond that which is known to IR; it is the dimension of sight and sound, it is the dimension as vast as space and as timeless as infinity. It is the middle ground between light and shadow, between science and superstition. And it lies between the pit of our fears and the summit of our knowledge. This is the dimension of imagination. It is an area which we call the Insight Engine. But seriously, we expect you will find these ideas neither groundbreaking nor surprising. I'm sure that many of you will recognize the tactics as being those you use regularly. You will likely also notice that implementing these ideas rigorously requires more capacity than most higher education institutions currently have for work integrated to this level. We are hopeful that the concrete examples we provide will allow you to better understand how the model can be used as an ideal or checklist. But the rigor and comprehensiveness of the approach can be varied to apply to projects large and small. The model we are describing today emerged from an institution-wide initiative that I will briefly describe later in the presentation. Phoebe Wakhungu will now describe further the context for this work, and give you some background on the issues that we believe warrant this type of approach. Phoebe?
[Phoebe Wakhungu] Thank you, Vic. I will describe the context for this work and highlight some important issues that warrant this approach. As we already know, at higher education institutions, traditional approaches used by institutional researchers are shaped by siloed nature of our institutions, especially for those of us who work in large public universities. Though we say that institutional researchers take an enterprise view, it is common that IR offices focus primarily on student data, supplemented with information about the curriculum and staff, but less frequently delve deeply into other areas like finances, space utilization, instructional design, and philanthropic giving. There are others at our institutions that provide analytic and decision support in these areas, including colleagues in finance, teaching and learning, research administration, and so on. Technology's becoming more and more pervasive throughout our lives. Some of us are beginning to use online behavioral data captured from course management systems. Communicating results through Tableau or other dashboard tools is also pervasive in IR. Indeed, the technological revolution is reshaping how we do our work. Pervasive technologies also shape expectations among our clients and colleagues. The digital native students and staff we support expect us to use the types of service technologies that commercial businesses increasingly rely on to compete for and attract customers. The current global pandemic, though winding down, we hope, has not only accelerated the digital transformation at our institutions, but also made us realize how much we rely on and use technology in our work. The pandemic has also raised our consciousness about inequalities in our society. Indeed, technological advancement does not apply to all people equally. Any thoughts of embracing new technologies to advance service must consider that we will widen the digital divide unless we make a primary objective of our work narrowing the digital and other divides. Our slide shows a quote from Cathy O'Neil's seminal book, Weapons of Math Destruction, that goes beyond the issue of access to and experience with technologies. She describes how seemingly logical coding can mask and thereby amplify social injustices since using the past to guide decisions will replicate past injustices. Another aspect of the problem that the Insight Engine addresses relates to the limitations of any single type of data analysis or methodology, many of which we often overlook when we offer any kind of interpretation. both quantitative and qualitative forms of inquiry, offer advantages and limitations. Quantitative data are abundant, readily accessible, and relatively easy to analyze. Qualitative data add nuance and richness, and most importantly, preserve the humanity of our students, staff, and faculty that is always often sanitized by quantitative methods. We tend to offer quantitative data as objective when it's often not so. For instance, we talk of a race as a characteristic of a person, whether they are Black, white, Hispanic, Asian, and so on. But that's not an objective statement as it is not based on reliably measurable physical or even biological characteristics. Race is a social construction that is particular to a geopolitical context. It carries with it all the weight of that context, history, and culture. Because of that, when we distinguish people by race. We are confining them to a specific group. This labeling has profound effects on how people treat each other. We must remember that numbers we analyze to present things that range from very concrete and acceptable to other things that will have much less consensus about. When we label or name constructs, we tend to think that it's a real thing because it has a label and yet it is not. Thus, it is both wrong and dangerous to mistake them as objective facts because we cover up the agendas and biases by suggesting, well, that's just the way it is. Let's look at the numbers. But in real sense, the numbers are biased because of underlying assumptions and values that we often take for granted or otherwise ignore. Another issue with the numbers is that we tend to treat correlation too often as causality. Despite our knowledge, we make statements like "race influences persistence." This stems from beliefs that metrics will present realities rather than the approximate proxy indicators of something that may not be well, very well agreed upon. The core issue is that we give numbers far more credit than they deserve. Also, quantitative research, design of questions on a survey and choice of response scale, data collection methods and selection of data, definition of model and interpretation of findings are influenced by beliefs and biases of researchers. We know very well that data are often used selectively to support agendas or to make our institutions look good. Qualitative research recognizes the need to account for beliefs, values, and experiences of researchers and how it affects their research interests, research questions, selection of methodologies, and interpretation of data and so on. And while qualitative research takes the context into primary consideration, it also limits generalizability due to smaller sample sizes. The research process of working with qualitative data is long and more time-consuming, and data interpretation and analysis are complex. Again, each approach has its advantages and limitations. Both provide necessary information, but neither is sufficient by itself. Like me, you probably have spent considerable time staring at numbers in tables and charts, trying to understand what they mean. We realize the data on their own are meaningless. They only mean something in terms of how we interpret them, which is affected by how they were collected, analyzed, and what we decide to do with them. Interpretations of findings and actions taken are influenced by human biases. When interpreting data, we must always remind ourselves that humans are not completely rational. They are rational, but with some considerable biases. Some of the biases are related to the way our minds process information such as the types identified by Tversky and Kahneman, including recency bias, primacy bias, confirmation bias, anchoring, and so on. Perhaps one of the most powerful confirmation bias is particularly vexing for us. People will search and interpret information in a way that confirms their preconceptions. Relatedly, we get different interpretations of the same information between diverse groups of people. For example, results from a student survey on academic advisors will be interpreted differently by academic advisors and the program director. Academic advisors would interpret the data based on their knowledge and understanding of what goes on at the ground level, while the director of the program will be looking for a general trend with the goal of improving the problem. So the question we need to be asking ourselves is, are the right people looking at the data, interpreting them, and deciding on what to do about them. I will call upon my colleague, Vic to provide details about the project and describe the Insight Engine model.
[Victor Borden] Thank you, Phoebe. Given the context of the problem that Phoebe just described, we would like to offer an ideal framework that we developed as noted earlier, as part of a university-wide initiative generously funded by the Lilly Endowment Incorporated as part of their Charting the Future program. I'll give you more project details later, but next, Seonmi Jin, who we all know as Sun, will provide further details on the Insight Engine model itself. Sun?
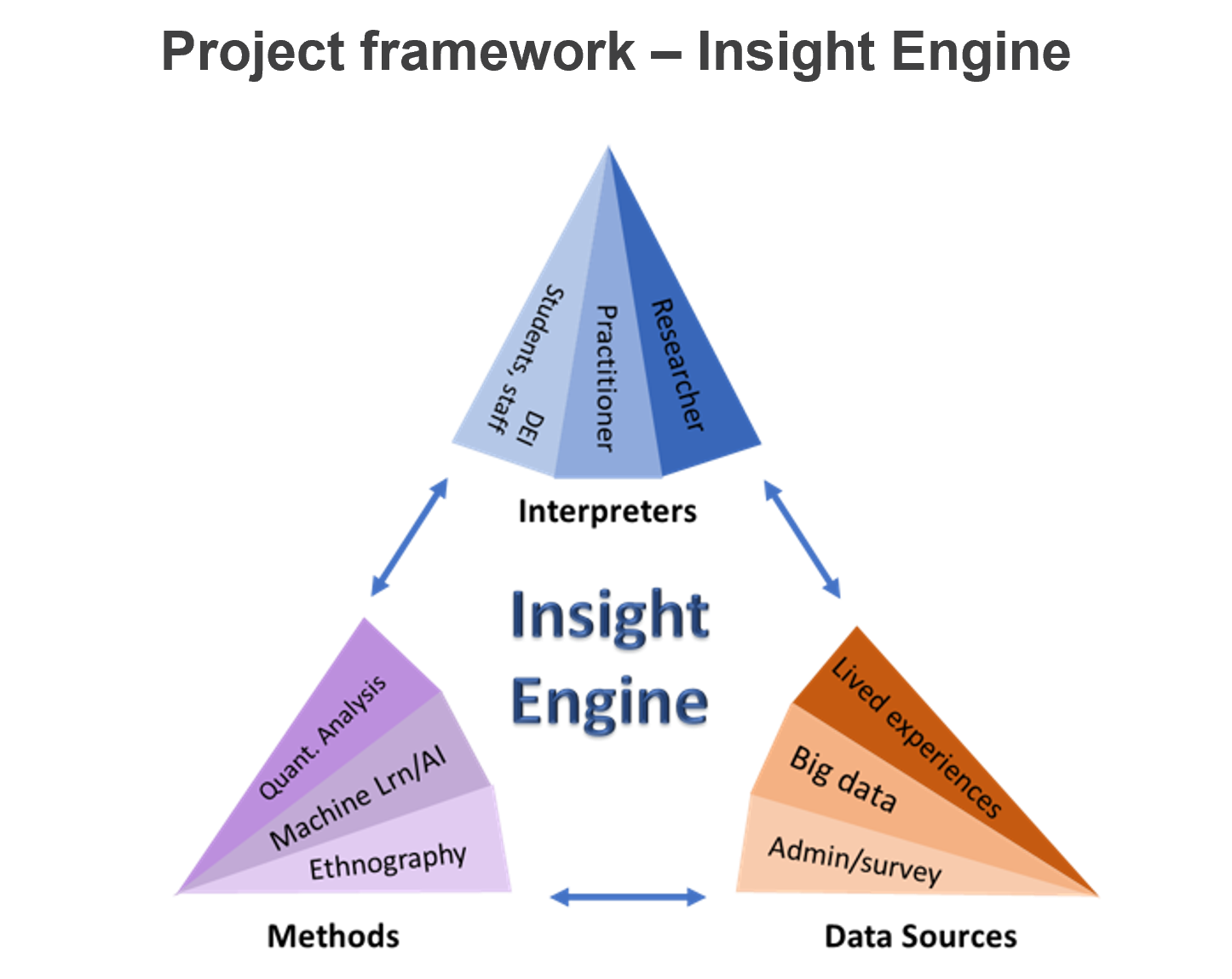
[Seonmi Jin] Yes. Thank you, Vic. I'll be describing for you the elements of the Insight Engine model and then turn it back to Vic to provide some examples of its use in the context of the large university- wide research project from which it emerged. The Insight Engine is built on the concept of triangulation that is found in several shapes and forms in the inquiry and the research design literatures. As we will describe it in the next few minutes, the triangulation works at two levels, so we call it triangular triangulation. When applied comprehensively, the process can be very rich and time-consuming. So the most comprehensive application should be reserved for high priority issues like student learning, persistence, completion, and outcomes, which is what our project focuses on. We presume that many of you pursue these same objectives in your work. And now I will unpack the idea of triangular triangulation, starting with the higher level of triangulation. There are three pillars of this triangulation: data sources, methodologies, and interpretations. The first two, data sources and methodologies, can be considered together. IR practitioners may most often find themselves in the lower-left point of this triangle. Using descriptive and inferential statistics to analyze quantitative data from administrative records, survey responses, and other collected or extant data sources. However, the practice of IR increasingly includes forays into the other two corners. The top point represents the behavior of data extracted from learning management systems, often referred to as learning analytics, and analyzed with machine learning and data mining techniques. The lower right point reflects increasing use of qualitative evidence, including student writing, participant and non-participant observation, focus groups, interviews, and so on. Each of these types of data and their associated methods of analysis provide different types of insights. Each has its limit, and so together they provide a more complete picture. And the third pillar of the first level of triangulation is interpretation action taking. Triangulation at this point is used to reduce what has been described by Argyris and colleagues as the gaps between espoused theory and theory in use. Espoused theory is reflected in what we say are the reasons why and behave as we do, whereas theory in use are the reasons that actually drive behavior. For instance, we may profess to support the success of diverse students on campus. But the actions we take and the environments we support might work against doing so. Triangulation of interpretation is achieved by bringing to the table the diverse perspectives needed to ensure that underlying assumptions are challenged and varying perspectives are considered, including those of the students, faculty, and staff whose lives will be affected by either inaction or action. In the process of interpreting and recommending actions based on institutional research, we should ensure that we consult with the practitioners and experts at our institution and elsewhere. Additionally, we need to consider the voice of the population involved in and affected by the processes and programs that we study. The triangulation of methodology and interpretation supports incorporating that voice adequately into research that is specifically designed to produce improvement in outcomes. And through our research, we found another such triangular triangulation model offered in health care research, although in this case the three components are sources of data, method of data collection, and method of analysis. In our model, we consider data collection to be an aspect of the methodology, not needing consideration for triangulation by itself. Instead, we add the distinguishing feature of this model, recognizing the need to triangulate interpretation to ensure that critical diverse perspectives are considered before any action is taken. Vic will now describe the project within which the model originates and give three examples of its application.
[Victor Borden] Thanks, Sun. As I noted earlier, the idea for development of the Insight Engine approach is tied to a generous grant from the Lilly Endowment Incorporated. Each institution developed a proposal to fund innovative programs and initiatives that deal with the current realities of post-secondary education, including the pending enrollment cliff and to produce talent needed for Indiana's economy. Indiana University assembled an executive steering group led by the institution's three executive vice presidents. I was asked to coordinate the development of the proposal. Initial ideas focused on the supply chain analysis which morphed into, one, a K–12 through workforce pipeline; two, expanded collaboration with K–12 districts and schools; and finally, a charge to leverage and integrate IU's expanding but not very well-integrated capacities to develop technology-infused interventions and improve student engagement, learning, completion, and ultimately career trajectories. The Insight Engine was the final layer added to the strategies. It was inspired in part by two keynotes at the AIR conference that I'm sure many of you attended. The first by Cathy O'Neil, author of Weapons of Math Destruction, who points out, as Phoebe earlier noted, that emerging technologies, such as predictive analytics and machine learning, reproduce and even amplify inequities unless we deliberately ensure that they do not. The second point, and where the name comes from, was Tricia Wang's keynote and especially her idea that quantitative data have been stripped of important aspects of humanity that belie the data. She further notes that qualitative inquiry restores those missing aspects that are crucial for transformative insight. This chart shows how the insight engine is being used to guide project activities. The rightmost column refers to the range of quantitative methods and data sources that we can bring to bear on these activities. These include traditional IR sources like administrative records, as well as the emerging behavioral data we can now harvest from online transactional systems, like our learning management systems and student activity systems. The middle column refers to the clustered targets of qualitative inquiry that we need to understand, including the students, faculty, and staff, which we engage in our curricular analytics and related student support development, those involved in developing and pursuing career objectives, and finally, the K–12 students, teachers, and staff with whom we collaborate to improve career and college readiness. The leftmost column, labeled "Expert Panels," refers to the types of expertise relevant to these three domains of pursuit. Analyzing and improving curricula, career planning and development, and K–12 collaborative partnerships for student success. So how do these concepts translate into action? I'll briefly describe three applications of the model. The first is related to one of our target populations, students who received Indiana's Promise Scholarship that provides free college for low-income students. The second example is the first pipeline model collaboration with four K–12 school district partners. And finally, I'll describe research we are conducting to understand who does and does not engage with these types of efforts to improve student success and career development. The progress and success of 21st Century Scholars is a statewide topic of interest in Indiana. The state distributed close to a hundred and seventy five million in aid through the 21st Century Scholars Program in fiscal year 2019, which is nearly half of all forms of aid distributed by the state and by far the largest single program. In addition, many campuses supplement the full tuition award with financial support for room, board, and expenses. In recent years, the state has been introducing more rigorous requirements for students to keep this generous scholarship, including that they've passed—not just take, but passed—30 credits of work annually. Even more recently, the state introduced the ScholarTrack system that require scholars to record each year progress on their completion plan, including the documentation of a student engagement event, a career planning event, and especially during a pandemic, the new ScholarTrack requirements on top of the traditional ones like FAFSA completion, have become even more problematic. So we created both a near-term and longer-term research and action agenda, bringing together the individuals from our campuses of IU who have the highest proportion of 21st Century Scholars to learn more about their challenges and the experiences of their scholars. Because of the very urgent need to ensure that scholars complete annual eligibility requirements, we analyzed extracts pulled from the state's ScholarTrack system to examine compliance behaviors among the scholars. We then developed a nudging campaign that increased requirement completion substantially within a month. We also developed a longer-term plan to analyze both the state's and our own data on scholar progress. Finally, we've engaged with our colleagues who support the program to use a series of qualitative inquiries to assess the experience of scholars in relation to the program requirements and institutional supports. The result of all these analyses will be processed by the experts that we have identified, including the program manager, senior administrators, and both faculty and doctoral students who have done and are doing research relevant to this programming population. The project has also reserved a pool of money to act on these findings of this research. The only stipulation to using that money is that any intervention we try must include an assessment component so we can determine first if the intervention has been implemented with fidelity, and if so, whether it works at a sufficient level to justify continued funding or possible expansion of an intervention. If not, we try something else. The second application I'll mention is our first K–12 partner collaboration. We're working with four school district partners from around the state to develop a pipeline focusing on eighth grade to second year of college timeframe. Indiana is among those states that have been linking administrative records across public systems. The Indiana Business Research Center based at IU has been contracted by the state to work on developing these data systems. And so we have within our institution the expertise needed to bring together the data from K–12, higher education, and the Indiana workforce. We'll develop a pipeline model for each school district that helps them identify areas of focus for improving student college and career readiness. The pipeline model system will be relatively simple, focusing on the flow at points of transition from one grade level to the next. And we're currently working with our partners to identify the key factors to explore in relation to student progress. We already have consensus, for example, an easy one, on the need to explicitly track students who are participating in the 21st Century Scholars Program when they first enter high school. We will also likely include basic demographics with regard to student race and ethnicity, gender, income status, like free reduced lunch eligibility, and participation in college readiness curriculum, including standard coursework like highest level of math and dual credits taken and so on. After we do the first analysis to understand where there might be a need for further investigation. We will work with our K–12 partners to identify those areas and plan with them multi-method approaches to that research, including further quantitative analyses and qualitative inquiries as appropriate to the problems that we collaboratively decide to pursue. Based on the research, we'll provide further technical and analytical support to our K–12 partners so they can try interventions and assess their efficacy. The final example of the Insight Engine's application is what we're referring to as take-up research. Specifically, we are seeking to gain insight into why students do and don't use the supports we make available. In parallel, we'll be conducting mixed-methods research on which faculty and staff do and do not engage with institutional efforts to improve student success. We're focusing on take-up as related to the types of initiatives and activities that the project is funding. One such initiative, for example, is shifting our current manual early warning system to an early alert system that employs engagement indicators from our learning management system. Toward that end, we will triangulate data collected through our manual student engagement roster system with behavioral analytics data from the LMS and data from the NSSE survey that we administer across all campuses every three years. A third focus area for take-up research is student use of career services, which we are in the process of redesigning. When my colleague who is leading up the career readiness aspects of the project mentioned to me this focus area, I wondered why she would want this as a focus when it was being changed. She made the compelling case, though, that would be useful to understand and make sure that the changes being made are aligned foremost with student needs and also with staff capacitance. The third area of focus for this take-up research will be on the use of curricular analytics to improve student success rates among traditionally underserved student populations in STEM and health-related courses. Specifically, we are focusing on courses that serve as gatekeepers to these in-demand career paths, which currently exhibit large gaps in attainment by race, ethnicity, and socioeconomic status. The findings from all this research will be presented to the expert panels that we have assembled to decide what types of actions or interventions can help us narrow performance and achievement gaps. It will also all be documented through an evidence library that is being created as part of the project. Finally, I'd like to note that one of the original intentions of developing the Insight Engine was a model for a new type of institutional capacity that we plan to sustain— create and sustain—as a result of the project. Specifically a project that would be referred to as institutional research and development, or perhaps even academic research and development. True to the initial purpose of the Charting the Future project, we believe that IU's future success depends on the institution's ability to harness the resources it has as a comprehensive statewide university to continuously innovate teaching and learning practices and experiences, as well as our ability to support students by relying increasingly on technology-infused interventions, or EdTech as we know it, that we develop and our partners develop with our particular array of learning environments to promote the success of all learners with special focus on those who have been less well served historically within our institution and in our state. Thank you for your time and attention, and I believe we'll now move to a live Q and A. Stephan?
[Stephan Cooley] Thank you so much. And thank you for sharing this wonderful model with us. It's interesting looking at it with the triangulation approach. As Phoebe mentioned, we tend to focus on this quantitative data. Everything should be quantitative. And it's cool to see triangulation applied in a different context. I was wondering, as you have gone through this process, what challenges or opportunities have popped up that you weren't expecting?
[Victor Borden] Thanks, Stephan. That's a great question. Challenges are—you can understand challenges are herding the cats, getting people together when you have resources and support, but you don't have direct supervisory links to these people. So it's a lot of teamwork that's involved. And of course, teamwork can be challenging, but on the other hand, it is essential to coming up with key solutions. So, you know, getting the time and attention of our colleagues. Thankfully, we have leadership support toward that end. So, so far so good. On the positive side though, we've, run into colleagues around our campuses who are doing things in this space. Who are really excited by the possibility of us integrating the work that's being done. And others who are really interested in learning from what others are doing, which hasn't been, we haven't been particularly effective at being a very large 100,000 student, eight-campus university. So there's a lot of interest, of course, because it's just starting and it has resources and all of that. The true test will be in the next year as we actually move forward on these projects. Phoebe or Sun, would either of you like to add to that? No? Okay. Next question, Stephan?
[Stephan Cooley] Thank you. So I was wondering if we could talk a little bit more about this idea of bias data. Phoebe made a really good point about if data are biased, then however we use them, it doesn't matter because it's going to give us biased results. And so I was wondering if you guys could talk a little bit more about that and maybe a little bit how you're kind of handling that in this project?
[Victor Borden] Sure. Phoebe, would you like to start?
[Phoebe Wakhungu] As we indicated earlier, we are saying that, okay, whichever type of data we use, there's some bias linked to it. So what we're doing is to reduce it, we are trying to use other ways of triangulation by using both qualitative data, quantitative, and also looking at the way we interpret it using the interpretation. So we're not just saying these are the results we have from this and so this is what we are going to look at. We're trying to look at both sides from the ones who give us the information from our own values and beliefs that we grew up, where we grew up, you know, what is inherent in us. And so you're saying I'm not just going to look at this data by myself. I'm going to call in other experts. I'm going to call the people who have these experiences. So that's how we're dealing with it. And that's why we are, we are bringing the issue of the Insight Engine. It's not one person's decision when it comes to analyses, when it comes to interpretation, and further we're involving everybody with who we are interacting with and even calling in other people who are specialists within the topics we are studying. Yeah.
[Victor Borden] Yeah, that's a good point. It's kind of related to what might be called co-design. When you involve your participants in your evaluations and research in the effort, you get their perspective in there and then it just takes it a step further. And I think from my experience, what I've noted is when you bring—literally systematically bring, intentionally bring— people to the table who you know will have differing perspectives so that one person may view it because the data aren't biased. It's people who are biased. It's the cognitive processes that are biased. There are intentional biases, but there are unintentional and just human processing biases as we mentioned. So people understand that, but it's when you don't want to— you want to avoid groupthink where people start supporting each other's views because they're only half represented at the table, certain perspectives. And of course, we've been so sensitized to that this last year with inequities and social injustices that we've seen before our very eyes. So we need to be very intentional about who we expose to the data and ask for their opinions of what it means and what can be done about it.
[Stephan Cooley] All right. Well, thank you guys very much. I think that's about all the time that we have. And thank you all for joining us for this presentation. If you want resources, there are resources linked in the session page. And other than that, I wish you to have a fantastic rest of the day and enjoy all the sessions. Thank you.